Bulk Ingest¶
Colectica provides a Bulk Ingest command to ingest many datasets at once, and to organize those datasets into studies.
Contents
Structure of Information to be Ingested¶
To use the Bulk Ingest command, first prepare the information to be ingested. The Bulk Ingest command takes a single directory as input. This directory should be structured like the following:
- Subdirectories
A study is created for each sub directory.
- Data files within subdirectories
A dataset description is created or updated, and placed within the appropriate study.
- CVS or Excel files within subdirectories with names matching a data file
These are treated as Metadata Input Files, and information from them is applied to the corresponding data file description.
- concepts.xlsx
Defines topics
- concordance*.xlsx
Defines equivalence among variables across datasets
A sample directory listing may look like this:
- Ingest_Root/
concepts.xlsx
concordance.xlsx
- Wave1/
household-data-wave-1.sas7bdat
household-data-wave-1.csv
member-data-wave-1.sas7bdat
member-data-wave-1.csv
- Wave 2/
household-data-wave-2.sas7bdat
household-data-wave-2.csv
member-data-wave-2.sas7bdat
member-data-wave-2.csv
- Wave 3/
household-data-wave-3.sas7bdat
household-data-wave-3.csv
member-data-wave-3.sas7bdat
member-data-wave-3.csv
- Wave 4/
household-data-wave-4.sas7bdat
household-data-wave-4.csv
member-data-wave-4.sas7bdat
member-data-wave-4.csv
In this example:
A topical concept system is created based on the contents of
concepts.xlsx.Four studies would be created with the titles Wave1, Wave2, Wave3, and Wave4.
Within each study, two dataset descriptions are ingested.
Each dataset has a corresponding metadata input file, so metadata from that file is applied to the variables in the dataset.
Variable concordance is created based on the contents of
concordance.xlsx.
Perform the Ingest¶
When a Series is open, click the Bulk Ingest button.
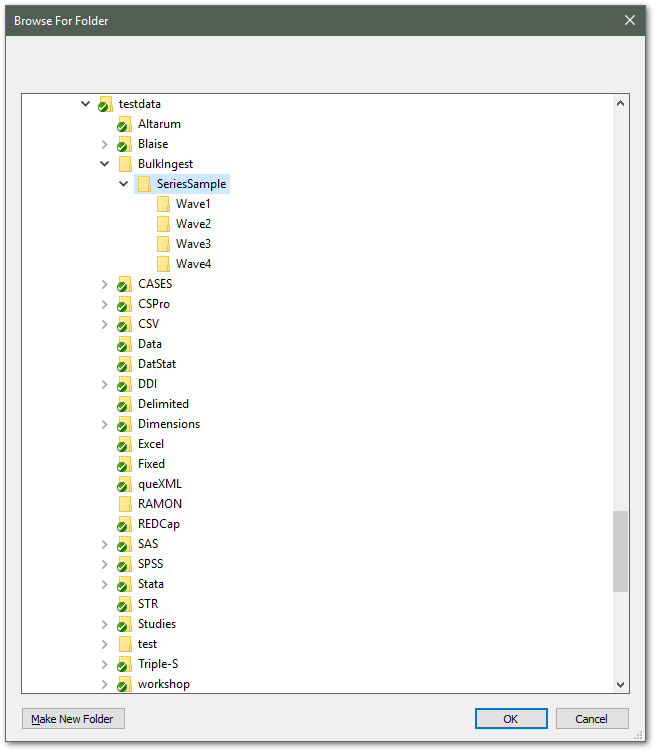
Choose the ingest directory. See above for the required structure of the directory.
Colectica will ingest the information. When finished, Colectica will show a summary of the updates to be made.
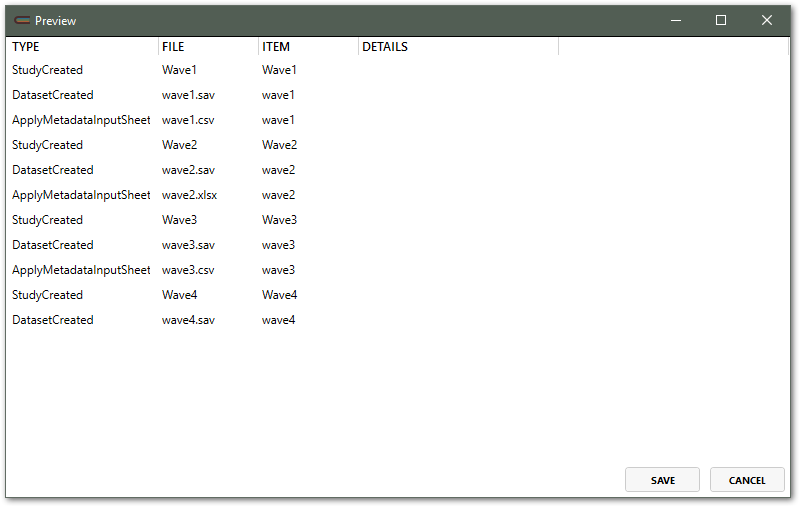
To apply the updates, click Save. To discard the updates, click Cancel.
Note
Summary Statistics are not automatically calculated for datasets ingested using this command.
Running the Ingest Again¶
The Bulk Ingest command can be run multiple times. During subsequent executions, any new studies or datasets will be added. Any existing datasets will be updated based on any changes detected in the metadata.
Directory Structure Details¶
Concepts Definition File¶
This file can be named either concepts.xlsx or concepts.csv.
For each line in the file, a concept is created. To specify a hierarchy, separate levels with colons.
A sample concept definition file looks like this:
Topic |
|
|---|---|
Demographics |
|
Demographics:Person |
|
Demographics:Location |
|
Family |
|
Family:Partner |
|
Family:Children |
|
Work |
|
Work:Job |
|
Work:Commute |
Subdirectories¶
For every first level subdirectory, the Bulk Ingest command determines whether a corresponding study already exists within the series. A study is determined to be a match if it has a UserID with the key BulkIngestSource that matches the name of the subdirectory.
If no match is found, the command creates a study and adds it to the series. The study title is set to the name of the subdirectory. Colectica also sets a UserID with the key BulkIngestSource set to the name of the subdirectory. This means you can safely edit the title of the study, and Colectica will still match the subdirectory with the study during future runs.
Data Files¶
For every file in a subdirectory, the command determines if the file is a data file. The following file types are treated as data files:
SAS files (*.sas7bdat)
SPSS files (*.sav)
Stata files (*.dta)
For each data file, the command determines if a matching dataset description already exists within the study. A match is determined when an existing dataset description has a Data File Location that matches the path of the data file. If no matching dataset description exists, the command creates one and adds it to the study. If a matching dataset description is found, the command updates the dataset description with any changes detected.
Metadata Input Sheets¶
If a CSV or XLSX file with the same name as the data file exists in the same directory, it is treated as a metadata input sheet. Information is applied to the dataset’s variables.
Download a Metadata Input Sheet template.
A sample metadata input sheet looks like this:
Name |
Label |
Description |
Type |
Codes |
|---|---|---|---|---|
name |
The name of the respondent |
Text |
||
marstat |
The marital status of the respondent |
A longer description can go here. |
Code |
1, Single | 2, Married |
age |
The age of the respondent |
Numeric |
See also
For details on the format and content of metadata input sheets, see Apply a Metadata Input Sheet.
Concordance Definition Files¶
These files can be named concordance*.xlsx or concordance*.csv.
Multiple files are allowed. For example, the following files could all exist and would all be applied:
concordance-demographics.xlsxconcordance-family.xlsxconcordance-work.xlsx
The concordance definition file allows the following columns:
Name: a name for the ConceptualVariable to be created.
Label: a label for the ConceptualVariable to be created.
Description: a description for the ConceptualVariable to be created.
Topic: the topical group to which the ConceptualVariable should be assigned.
All other columns are used to locate datasets. The column name should match the name of a data file.
The Bulk Ingest command performs the following actions when processing a concordance definition file.
- For each row of the concordance definition file
A ConceptualVariable is located or created
The ConceptualVariable is assigned to a topical group based on the Topic column
For each dataset locator column, a variable with the specified name is located within that file
That variable is declared comparable with the row’s ConceptualVariable by creating a relationship to an appropriate RepresentedVariable, which in turn has a relationship to the ConceptualVariable.
A sample concordance definition file looks like this:
Name |
Label |
Topic |
wave1 |
wave2 |
wave3 |
wave4 |
custom:Comparability |
|---|---|---|---|---|---|---|---|
age |
The age of the respondent |
Demographics:Person |
age |
age |
age |
age |
Here are some notes about how the data compare across waves. |
sex |
Sex of the respondent |
Demographics:Person |
sex |
sex |
sex |
sex |
|
country |
Country in which the respondent lives |
Demographics:Location |
country |
country |
country |
country |
Custom Fields in Concordance Definition Files¶
Custom fields can also be applied to variables using a concordance definition file.
To apply information in custom fields on a conceptual variable, add extra columns that begin with custom:.
For example, to add a field named Comparability, add a column named custom:Comparability.